Living on the edge: An introduction to edge computing

By Steve Lepine, EXFO -- Remember when the cloud concept was introduced? It was revolutionary, with its unlimited data storage, and anytime, anywhere access. But as more and more data has migrated that way, requirements for the cloud’s centralized storage capacity continue to grow. Are a few centralized points of storage and analysis of our data still the right way to go (i.e. few locations, with big storage capacity)? Does that model still fit today's needs in terms of machine learning, artificial intelligence, fast decision making and real-time processing? This article discusses why pushing content and services from a centralized cloud architecture to distributed data centers at the edge of the network can be beneficial to operators as they drive new 5G services, like IoT, to their customers. We’ll also take a look at some of the parameters that must be considered in an edge networking strategy.
What is edge computing and why it’s needed
Edge computing deployments are comprised of headends re-architected as data centers (HERDs) with the goal of bringing intelligence, storage capacity and computing power closer to customer devices and consequently reducing latency. The intention of edge computing is to pre-analyze some data, keep necessary intelligence that requires real-time access close to the premise and offload the remaining data to a cloud-based, mega-data center. This model also serves to avoid fiber scarcity since, as traffic between the edge and the central cloud is reduced, the need for longer-run fiber deployments is reduced. Of course, connecting a multitude of edge devices will lead to an increase in shorter-run fiber deployments but that can be managed individually by each operator. This model is also attractive in terms of data security, as not all network traffic is exposed to outside networks.
To further illustrate the concept of HERD, let’s use sheep in a play on both words and imagery (see Fig. 1 "Sheep"). As we decentralize the cloud, we break apart the herd, sending individual sheep (i.e. data, computing power) closer to the edge. As operators offload the exchanges between the data center and customer devices, more computing is moved to the edge. Do operators have the bandwidth, the latency and the fiber necessary for a successful network edge deployment? Are infrastructure and processing power optimized and ready for this? If not (as seen with the sheep in the right-hand bottom corner at end of Fig. 1) you, and consequently your customers, could have a problem. So, operators need to make sure that everything is working right the first time.
New business-services models, including IoT, are emerging. It’s like a wild west of technology services with a multitude of greenfields to explore. Top of the crop today are cloud gaming, healthcare sensors, retail applications, enterprise cloud, artificial and virtual reality. With market sizes of $95 billion and $160 billion for retail and cloud gaming respectively , operators will do what they must to improve service delivery in order to get the biggest possible bite of that revenue pie.
Let’s focus on the ultra-low latency requirements for IoT and the connection between latency and edge computing. There is a maximum distance from the premise that a device can be after which it can’t maintain the desired levels of ultra-low latency. That's why operators are gearing up to bring parts of the cloud-based data center closer to end devices. To illustrate, let’s look at self-driving cars. While on the road, a self-driving car (an example of an ultra-low-latency IoT device) needs to make decisions, yet that car needs to process additional data in order to make decisions that are well-informed. Can I turn at this intersection, specifically at this time of day, and in which direction(s)? Since those decisions must be made almost instantly, if that data was stored far away in the cloud, there would be an accident before information could be accessed to make that decision.
With the amount of data generated by connected cars and the explosion of IoT devices, a major increase in network traffic is anticipated. And as mission critical services like remote surgery—the ultimate ULLC IoT use case—come online, increased speed, ultra-low latency and increased bandwidth availability will become primordial to the success of IoT services. So, in an IoT world, quick decision-making requires ultra-low latency communications (ULLC), which means bringing intelligence closer to the premise (i.e. closer to the customer).
Where should the edge reside?
The edge is not a single location, in fact there are several levels of edge computing (see Figure 2) defined by how close they reside to the customer. So, how many levels are best? The answer's not set in stone. It’s up to individual operators to maximize the number of levels they need based on their own particular circumstance.

Edge computing facilitates the delivery of some of today’s new applications by bringing real-time processing closer to the customer device. As shown in Figure 2 real-time processing, even the performance of basic analytics, is now done closer to end devices to help offload the data center. In fact, the edge acts as a micro data center because data and information can be stored there—the type of information that IoT machines regularly exchange. Once all the computing and basic analysis is done, that data is transmitted to the cloud-based data center for storage or big data analysis.
The performance of (and storage of) basic analytics at the edge is done by micro data centers (or the edge cloud). As discussed, it's not the ideal place to store big data or perform high-level, big-data analysis, that’s meant for the central cloud data center. However, once the central data center has learned patterns (e.g. using machine learning) it can share that information with the edge, therefore the edge is constantly educated by the data center.
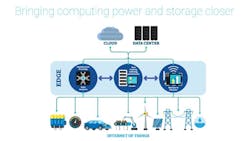
As discussed, latency is very critical to the success of new 5G services. The number of levels utilized in an edge computing architecture are directly dictated by the latency levels required for the services delivered (see Figure 3). Typically, the first edge level should not experience latency greater than 1-5 ms from the premise, with broadband service providers and internet access following with less stringent latency requirements. The closer you place your edge component to the premise, the more that edge component will be subject to the tighter requirements required for new 5G use cases such as ULLC. An edge component must be simple to deploy, capable of performing real-time processing and since there are no size standards for edge devices, can take the form factor seen fit by the operator—as opposed to a typical mega data center where everything is rack mounted and therefore standardized in terms of footprint. For example, an intelligent router could become an edge component, assuming it fits with the operator’s requirements.

What about traffic? We’ve mentioned that traffic is increasing, but in some places it will actually decrease. The amount of connected IoT devices is forecast to grow to 41.6 billion by 2025, generating a whopping 79.4 zettabytes (ZB) of data . So yes, the edge part will see its traffic increasing because of the many exchanges between all these devices. But, as traffic is uploaded to the edge, transfers to mega data centers will diminish. Exchanges between edge and data centers will continue to be critical, but the types of data processing qualified as “urgent” will be done locally (at the edge) with pattern learning done at the mega data center. And the type of data stored at the edge will change and evolve over time. Let’s illustrate this with an example.
Think of the mega data center as a big-box grocery store. Anything you want, you’ll find it there. But it may take thirty minutes, and lots of traffic, to get there. In contrast, your local convenience store is like the edge; you’ll find the common things, quickly accessible. You'll save time (i.e. latency) and avoid traffic (i.e. less local traffic at the edge as big data is offloaded to the mega data center). But what if you want something specialized, like sushi. One of two things can happen; either you'll go to the big-box grocery store to get it, or if people in your neighborhood consume sushi often enough, the convenience store will stock it because sufficient demand makes sense for them to do it.
Simply put, there is no single response about where and what the edge should be—the edge is wherever and whatever you want it to be. Its location is determined by a needs evaluation together with an analysis of available resources. There is however a direct connection between distance to an edge site and latency—the closer an edge site is to end devices or users, the lower the latency. The farther the edge is from an end user (e.g., or IoT device), the higher the latency. At the same time, the farther the edge is from the end user, the fewer number of sites are needed to store all the data (see Figure 4).

Do it right and do it smart: design and implementation challenges of edge computing
In terms of the design and implementation of edge computing, service providers are faced with a two-pronged challenge. On one hand, they have many new requirements; on the other hand, each requirement comes with its own set of challenges. Meeting these requirements will require a previously yet unseen level of performance and flexibility from networks which may involve drastic transformations.
For service providers, such a transformation touches almost every level of their business, from a deep network infrastructure evolution and massive rollouts, to updated processes and operations, to new services and new business models. Successfully managing evolving networks includes densification, virtualization—all done at minimal cost and low impact on customer experience. The amount of consumption and expectations of user experience means that the scale and the capabilities of edge computing will be more critical than ever. And automation and artificial intelligence will be critical to help address complexity and increase resource efficiency, including team productivity. The most challenging part is that all this is happening at the same time. In this context, doing it right means doing it smart. Those who do it right, will find the right balance, standing on that fine line where tighter network requirements meet heavy and growing challenges. They’ll optimize investments, making efficient use of their existing network.
A major challenge is the minimization of CAPEX since going blindly to the edge can be costly. Questions need to be asked and answered. Can existing network elements be leveraged? What needs to be offloaded from the cloud to the edge and what kind of real-time processing is required? Going back to latency, an evaluation is required in order to determine how to achieve new low latency requirements. Do operators need to switch to low latency DOCSIS? Is their infrastructure ready? All these questions must be addressed upfront, as the answers will have a direct impact on processing power and on the size requirements of micro data centers residing at the edge.
With massive fiber deployments at the edge, operators want to deploy everything right the first time. They don’t want increased truck rolls to become their new reality if each time a service is activated, nothing is working properly. So again, being prepared and planning properly is the best path forward.
Best-practice testing at the edge
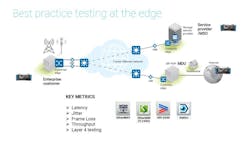
To discuss best-practice testing at the edge, let’s take a look at a simple network design example (see Figure 5). Several key metrics need to be tested and accounted for including latency, jitter, frame loss, throughput, transceivers, and increasingly, layer 4 testing. Transceiver testing is an important requirement, with data centers needing to test up to hundreds of transceivers within a short time, sometimes daily.

1. Emil Sayegh, “Is the Cloud on ‘Edge’? Dissecting Edge Computing’s Long-Term Impact on Cloud Strategy”, Forbes, May 21, 2020. https://www.forbes.com/sites/emilsayegh/2020/05/21/is-the-cloud-on-edge-dissecting-edge-computings-long-term-impact-on-cloud-strategy/#7ecfbac1692e
2. Carrie MacGillivray, David Reinsel “Worldwide Global DataSphere IoT Device and Data Forecast, 2019-2023”, IDC Research, May 2019.
Steve Lépine is Product Specialist, Transport and Datacom, at EXFO. Steve is an expert in Ethernet and Fibre Channel technologies. He has over 18 years of experience with EXFO in T&D. Steve was involved for 15 years as FPGA designer in R&D. He is a key contributor in the development of several test applications for high-profile product lines such as the NetBlazer, Power Blazer and BV series. Steve holds a bachelor’s degree in Microelectronics from Université du Quebec à Montréal (UQAM).

