Strategies for increasing system availability
Installing redundant cable runs can simplify maintenance and save money.
The power crisis in California demonstrates the continuing need for power protection. Every network installation is susceptible to various power problems, such as surges, spikes, brownouts and blackouts-especially during unstable or adverse conditions. The question is, "Is your network adequately protected from these inevitable events, and how well can you weather the storms?"
Building a power or cabling infrastructure that is reliable is no longer enough. Managers and supervisors are now demanding availability, regardless of external circumstances and conditions.
Availability vs. reliability
The difference between reliability and availability boils down to the length of time that a system needs to be operational. Reliability can be thought of as the probability or likelihood that a non-repairable system will continue to operate within a finite or limited mission time without experiencing any failures. Availability, sometimes referred to as "inherent availability," is the likelihood that a repairable system will continue to operate at some time in the future, given an infinite mission time. E-commerce and e-business demands of today require availability because business is conducted around the clock, and must continue indefinitely. Anything less than 100% uptime translates directly into lost revenue.
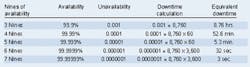
Downtime and the potential for lost revenue have led to the contemporary industry buzz words known as "the nines" of availability. The number of nines is the percentage of time that a given revenue-generating system, piece of equipment, or facility is available. To translate this into downtime, the un-availability is required. Unavailability = 1 - availability.
To compute the hours of downtime, multiply the unavailability by the number of hours in each year (8,760 hours/year). To convert this into minutes of downtime, simply multiply this result by 60 minutes/hour. Then, to convert this into seconds of downtime, multiply the result by 60 seconds/minute. The table (page 20) illustrates the decrease in downtime with the increase of nines of availability.
Redundancy
The availability of a repairable system is dependent upon the system's ability to operate, even if a component or subsystem fails. Redundancy is required to achieve this. Paralleling systems, subsystems and components is a way to add the redundancy and extra protection that can greatly improve a system's overall availability.
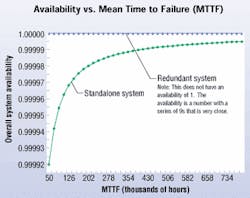
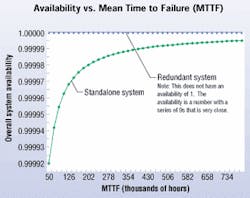
The figure "Availability vs. Mean Time to Failure" (above) illustrates the impact that redundancy can have on overall system availability. The graph represents a basic data center configuration, with and without elemental redundancy. Paralleling a component with a high failure rate has a greater impact on system availability than improving the mean time to failure (MTTF) of that component.
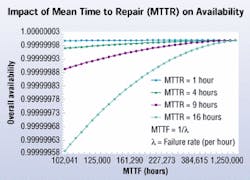
The figure "Impact of MTTR on Availability" (below) illustrates how decreasing the mean time to repair (MTTR) can have a significant impact on improving availability.
The following factors are associated with MTTR and can impact availability:
Response time: The time elapsed between the initial failure and the time at which the person who can resolve the problem is notified. There is no advantage in having a long linear chain of command. Recovery time can be minimized by immediately notifying the right person who can resolve the issue. If several people need to be notified, it should be done concurrently or after the key repair person has been notified.Travel time: The correct technician may not always be on site or in the immediate vicinity when a problem occurs. Travel time is the time it takes for that person to get to the appropriate problem area. Having service-level agreements can ensure that a qualified technician is on site within a given timeframe.Time to diagnose: In the majority of cases, some investigation will be required to identify the cause of the problem or to isolate the specific subsystem or component that needs to be replaced or repaired. Time to diagnose is the time it may take to determine the correct course of action. This can vary with the system's complexity.Repair, replacement or recovery time: Some problems can be repaired, while self-contained modules may only need to be replaced with a new module. Other systems may need to warm up, restart, or reboot. This time period accounts for the time it takes to get a system fully operational again, once the actual repair work has begun. Components should be selected that minimize this timeframe.Redundant cabling availability model
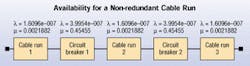
Using a simple availability block diagram, you can calculate the availability of a power path and measure the impact that adding a parallel path will have on availability.
The figure "Availability Block Diagram For a Non-redundant Cable Run" (page 23) illustrates a potential power path leading to a piece of equipment. The availability of this basic model is 0.9997776.
The availability of the same system with the added redundancy of a second, parallel power path increases to 0.99999995. This simple example demonstrates how paralleling a second power path clearly improves the overall availability. As more complex components are added to the power path, the availability will decrease. Therefore, more complex systems and less reliable components have a greater need for redundancy. λ represents the failure rate per hour and µ represents the recovery rate per hour. (The data for this model was taken from the IEEE Gold Book. The simulation was performed using MEADEP reliability prediction software from SoHaR, Inc.; www.sohar.com)
Dual-corded equipment
Dual power supplies and power cords are standard features of high-end servers, and can be used to boost system availability. The original purpose of the dual cord and power supply was to protect against failure of one of the server power supplies. If both power supplies are plugged into the same circuit or power source, then they both become susceptible to the same power problems and would suffer any loss of power simultaneously.
But if each power supply and cord is connected to a separate source of power, one source can experience problems or even fail completely, and the system will continue to operate from the second power supply and power source. For this to work, the building infrastructure must be designed with two independent sources. A building's power may be fed from two separate substations or even two separate utility companies. Having an alternative source, such as a generator and uninterruptible power supply (UPS), can also accomplish this redundancy-full redundancy all the way to the load.
Simplifying maintenance
Having redundant power cabling can also simplify routine preventative maintenance.
An entire power path can be shut down and isolated for maintenance, with a second power path available to power the equipment. Without it, managers would have to schedule downtime to work on critical systems, resulting in lost productivity and potential lost revenues. Companies simply can't afford to be down for even a moment. The capital expense to incorporate redundancy can be easily recovered by most companies after one maintenance cycle, which does not require that the network systems be shut down.
Installing redundant cable runs can offer the following benefits to your total installation:
- Provide a second power path in case of power supply, cord, or utility failure;
- Allow repair or replacement of failed components without shutting down the entire system;
- Simplified scheduled routine maintenance;
- Increased system availability.
Disaster planning
When systems fail or problems occur, even with redundant systems, it is important to take the appropriate action as quickly as possible. Of course, someone must first be aware that a problem exists. Remote management and monitoring systems are vital to reducing the time it takes to respond to and resolve problems that arise. Creating a comprehensive overall disaster recovery plan can help you develop policies and procedures that will guide personnel in the event of a failure or emergency.
The process of creating this plan can also determine whether the proper resources and equipment, such as monitoring and management systems, are in place to support the facility's availability goals.
Having a disaster recovery plan in place before an incident occurs is essential to maintaining high availability. Anything that can be incorporated in the disaster recovery plan to minimize each of the time factors previously discussed will reduce recovery time and improve availability. Having service technicians on site with pagers, storing spare parts, incorporating modularity, installing bypass systems, and paralleling systems can aid in the maintenance and service process without causing downtime, and also contribute to overall availability.
Following these guidelines on redundancy, MTTR, and disaster planning will result in higher availability.
Joe Wiley is an engineer with American Power Conversion's Availability Science Center (www.apcc.com).
Cabling Installation & Maintenance Story Ideas
null
Do you have an idea for a story on system design, installation, maintenance or troubleshooting? Send it to:
Patrick McLaughlin,
Chief Editor
Cabling Installation & Maintenance
98 Spit Brook Rd., Nashua, NH 03062-2801
tel: (603) 891-9222, fax: (603) 891-0587
e-mail: [email protected]

